【Python】「ValueError: The truth value of ~ is ambiguous. Use ~」の解決方法

こんにちは、にわこまです。
今回は、pythonで配列の比較を行う際に発生するValueErrorの解決方法を紹介します。比較だけを行うならValuErrorは発生しませんが、その比較を行った結果をif文などで利用するとValueErrorが発生します。
誤字脱字や分からない点、解決してほしい問題がありましたらご連絡お願いいたします。
メールまたはTwitterのDMまで!
スポンサードサーチ
配列の比較に関するValueErrorの解決方法
all関数またはany関数を使う
上記の関数を使うことで配列の比較に関するValueErrorを解決することができます。
そもそも「配列の比較に関するValueError」とは、「比較する要素が1つでないため、全てTrueならTrueなのか、1つでもTrueならTrueなのか、分からない」というエラーです。
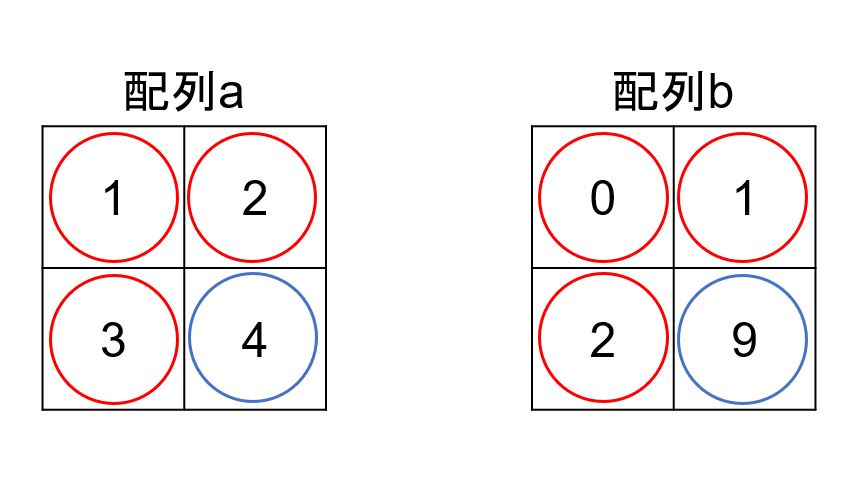
例えば、以下の図の配列aと配列bを「a > b」のように比較したいとします。赤丸の要素の比較では配列aの要素の方が大きいですが、青丸の要素の比較では配列bの要素の方が大きいです。
このとき、「a > b」をTrueとしたいのかそれともFalseとしたいのか分からないというのが、今回のエラーです。
今回は、numpyライブラリとpandasライブラリで発生する配列の比較に関するValueErrorの解決方法を紹介します。
numpyライブラリのall関数はこちら
numpyライブラリのany関数はこちら
pandasライブラリのall関数はこちら
pandasライブラリのany関数はこちら
エラーのサンプルコード1(numpy)
エラーが発生するサンプルコードとその実行結果を以下に示します。
import numpy as np
a = np.array([[1, 2, 3],
[4, 3, 7],
[3, 5, 8],
[9, 6, 3]])
b = np.array([[1, 4, 3],
[8, 3, 1],
[6, 6, 0],
[3, 6, 9]])
if(a > b):
print(True)
=== 実行結果 ===
Traceback (most recent call last):
File "valueerror_array.py", line 13, in <module>
if(a > b):
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
上記のコードは配列aと配列bを比較し、配列aの要素の方が大きければTrueと表示するコードです。
13行目の「if文」で、条件文を「a > b」としているため、エラーが発生しました。
条件文を「np.all(a>b)」または「np.any(a>b)」とすることで解決することができます。
エラーを解決したサンプルコードとその実行結果を以下に示します。(「np.all()」:全てTrueのときTrueと判定したい場合)
import numpy as np
a = np.array([[1, 2, 3],
[4, 3, 7],
[3, 5, 8],
[9, 6, 3]])
b = np.array([[1, 4, 3],
[8, 3, 1],
[6, 6, 0],
[3, 6, 9]])
if(np.all(a>b)):
print(True)
else:
print(False)
=== 実行結果 ===
False
エラーを解決したサンプルコードとその実行結果を以下に示します。(「np.any()」:1つでもTrueであればTrueと判定したい場合)
import numpy as np
a = np.array([[1, 2, 3],
[4, 3, 7],
[3, 5, 8],
[9, 6, 3]])
b = np.array([[1, 4, 3],
[8, 3, 1],
[6, 6, 0],
[3, 6, 9]])
if(np.any(a>b)):
print(True)
else:
print(False)
=== 実行結果 ===
True
エラーのサンプルコード2(pandas)
エラーが発生するサンプルコードとその実行結果を以下に示します。
import pandas as pd
df = pd.DataFrame([[3, 2, 3],
[4, 3, 7],
[6, 5, 8],
[9, 6, 3]],
columns=["X", "Y", "Z"],
index=["Crow", "Duck", "Eagle", "Flamingo"])
if(df["X"] > df["Y"]):
print(True)
=== 実行結果 ===
Traceback (most recent call last):
File "valueerror_array.py", line 10, in <module>
if(df["X"] > df["Y"]):
File "C:\…\pandas\core\generic.py", line 1326, in __nonzero__
raise ValueError(
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
上記のサンプルコードはデータフレーム(DataFrame型)のカラムXとカラムYを比較し、カラムXの方が大きければTrueと表示するコードです。
10行目の「if文」の条件文を「df[“X”] > df[“Y”]」としているため、エラーが発生しました。
条件文を「pd.DataFrame.all(df[“X”] > df[“Y”])」または「pd.DataFrame.any(df[“X”] > df[“Y”])」に変えることで解決することができます。
エラーを解決したサンプルコードとその実行結果を以下に示します。(「np.all()」:全てTrueのときTrueと判定したい場合)
import pandas as pd
df = pd.DataFrame([[3, 2, 3],
[4, 3, 7],
[6, 5, 8],
[9, 6, 3]],
columns=["X", "Y", "Z"],
index=["Crow", "Duck", "Eagle", "Flamingo"])
if(pd.DataFrame.all(df["X"]>df["Y"])):
print(True)
else:
print(False)
=== 実行結果 ===
True
エラーを解決したサンプルコードとその実行結果を以下に示します。(「np.any()」:1つでもTrueであればTrueと判定したい場合)
import pandas as pd
df = pd.DataFrame([[3, 2, 3],
[4, 3, 7],
[6, 5, 8],
[9, 6, 3]],
columns=["X", "Y", "Z"],
index=["Crow", "Duck", "Eagle", "Flamingo"])
if(pd.DataFrame.any(df["X"]>df["Y"])):
print(True)
else:
print(False)
=== 実行結果 ===
True
まとめ

今回は、pythonで配列の比較を行うときに発生するValueErrorの解決方法を紹介しました。numpyライブラリやpandasライブラリの配列を比較するときによく発生します。
改めて解決方法を以下に示します。
all関数またはany関数を使う
all関数は、「全てTrueのときTrueと判定したい」場合に使います。
any関数は、「1つでもTrueであればTrueと判定したい」場合に使います。
解決してほしいエラー、問題などがありましたらメールまたはTwitterのDMまで!
最後までお読みいただきありがとうございます。
スポンサードサーチ
